SAP에서 큰 파일을 처리하는 방법은 무엇입니까?
SAP에서 효율적인 작업을 위해 올바른 파일 처리
이 기사에서는 SAP에서 효율적인 작업을 위해 원시 텍스트 데이터를 사용하는 것이 바람직한 이유, 장점은 무엇이며, 훨씬 더 효율적으로 일하기 위해 더 작은 텍스트 조각으로 분해되어야하는 이유는 무엇인가?
SAP에서 큰 파일을 처리하는 방법은 무엇입니까?
큰 데이터는 매일 점점 더 많은 청크에서 다가오는 엄청난 양의 정보입니다. 그들은 모든 연결된 스마트 폰, 컴퓨터 및 전 세계의 스마트 TV 및 기타 스마트 시스템과 같은 모든 소비자 장치에서 왔습니다. 이것은 세계의 구조와 특히 인간을 더 잘 이해할 수있는 중요한 정보입니다. 또한 실제로 많은 다른 분야에서 마케팅 전략을 향상시키는 데에도 사용됩니다.
모든 파일이 네트워크 나 컴퓨터 하드 드라이브에서 특정 장소를 차지한다는 사실부터 시작하겠습니다. 즉, 볼륨이나 크기가 있음을 의미합니다.
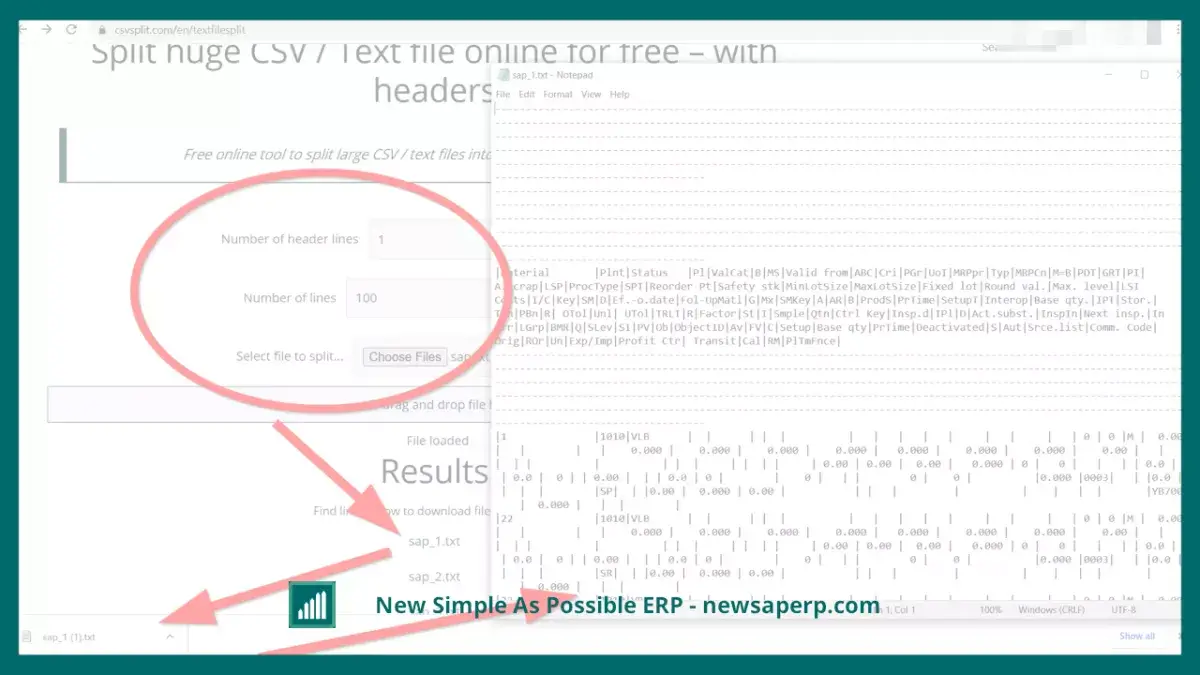
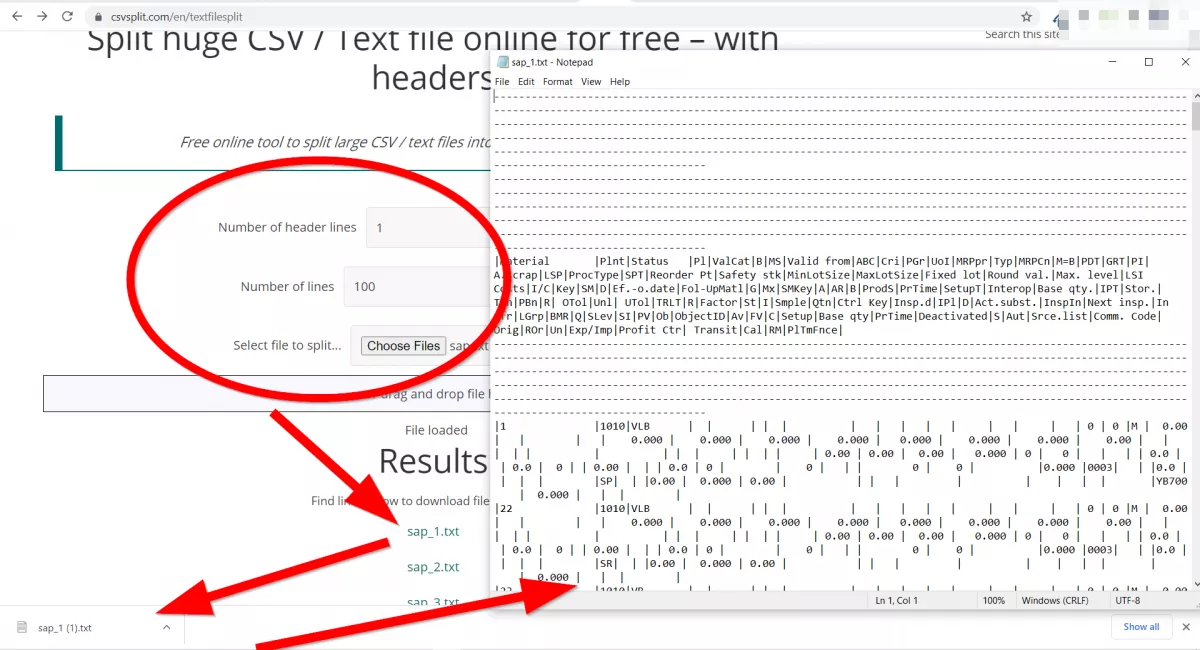
간단히 말해서, 빅 데이터는 더 크고 더 복잡한 데이터 세트, 특히 비표준 소스의 데이터 세트입니다. 이 데이터 세트의 크기는 너무 커서 기존 처리 프로그램이 처리 할 수 없습니다. 따라서 해당 파일로 작업 할 때는 온라인으로 EXT 파일 스플리터가 필요할 수 있습니다.
작업 과정에서 웹 마스터는이 정보를 사용하여 원시 형식으로 보내고 처리하기가 어려운 대용량 파일을 작성, 저장 및 보낼 것입니다. 이 문제를 해결하기 위해서는 온라인으로 텍스트 파일을 분할하는 프로그램이나 서비스를 사용할 수 있습니다.
SAP 란 무엇이며 큰 데이터에서 어떻게 사용됩니까?
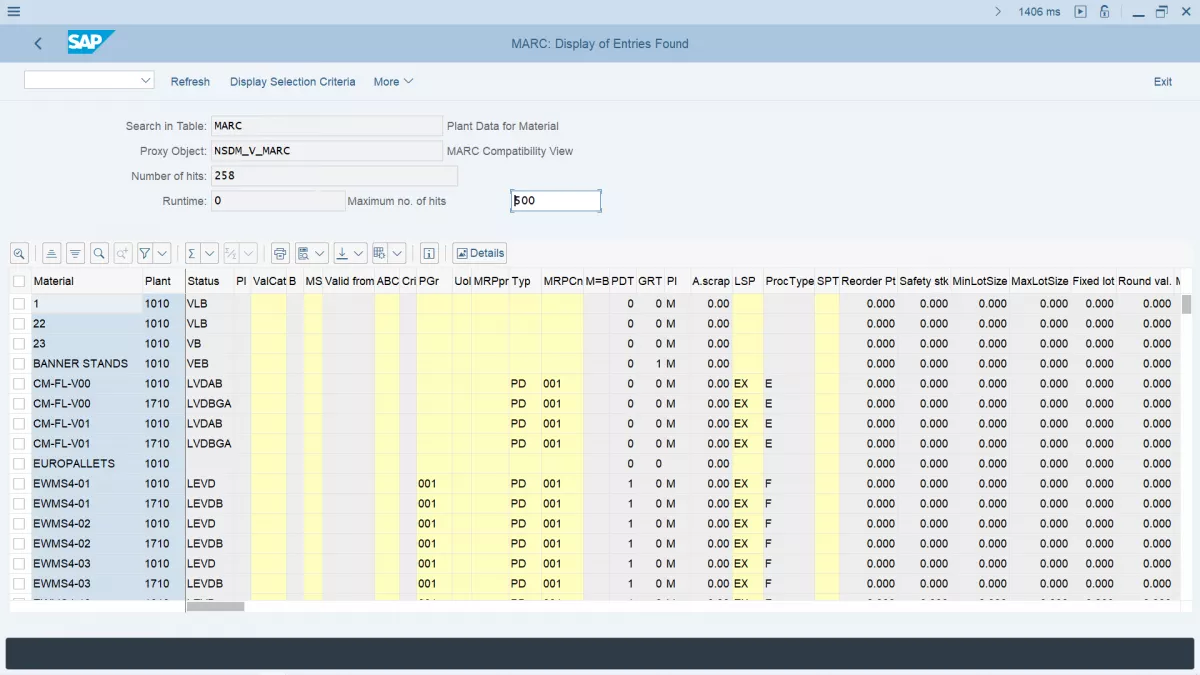
이러한 정보를 분석하려면 SAP 시스템이라는 특수 소프트웨어가 사용됩니다. 다른 영역을 사용하여 작업하는 많은 제안 사항이 있으며 사용자 정의가 만들어지고 필요한 작업을 더 쉽게 수행 할 수 있습니다.
데이터 처리를위한 응용 프로그램이 사용되는 이러한 분야 중에서, 먼저 큰 데이터 및 SAP를 사용하기 위해 다음과 같은 산업을 단독 할 수 있습니다.
SAP 중 하나는 로컬에서만 작동하는 응용 프로그램 (소위 클래식) 및 클라우드 시스템 작업을 전문으로하는 옵션을 구별 할 수 있습니다. 그럼에도 불구하고 네트워크 중단 및 다른 예상치 못한 상황이 발생할 때 오류 및 데이터 덤프의 가능성을 줄이기 위해 모든 경우에 큰 파일을 더 작은 파일로 분할 할 수있는 모든 경우가 더 효율적이라는 것을 보여줍니다.
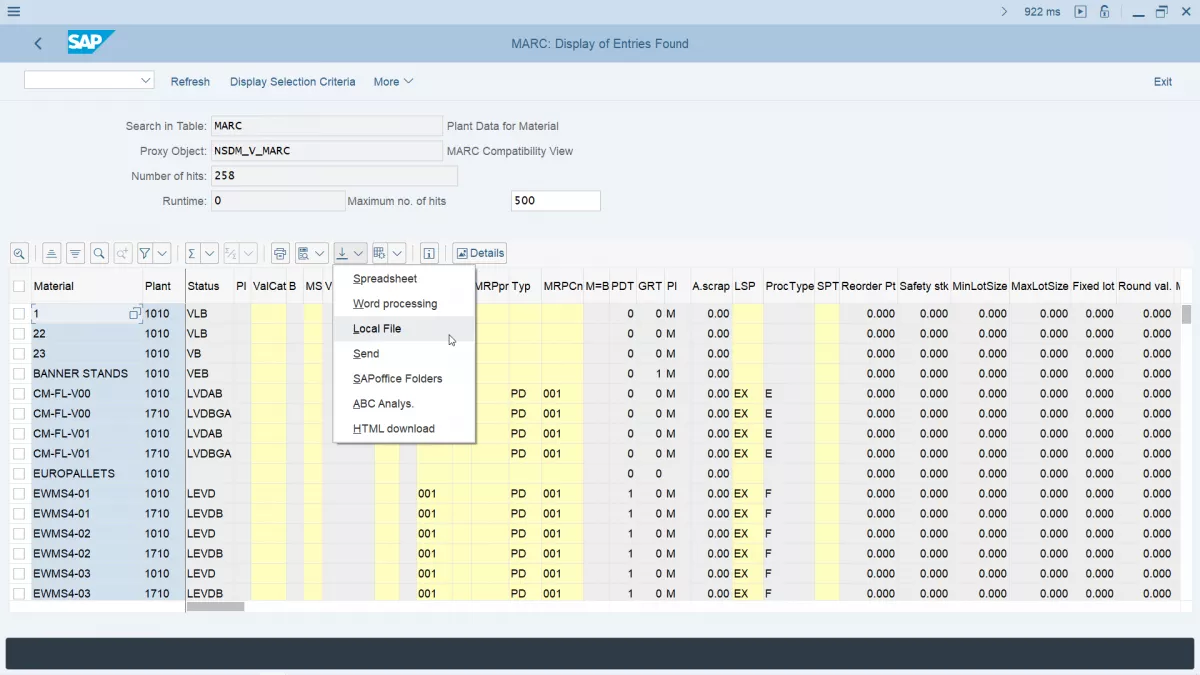
또한 일부 SAP는 편리한 형식으로 데이터를 내보내는 것을 지원하지 않습니다. 왜냐하면 그들이 매우 많은 데이터로 읽기 및 작업을 읽고 일하는 것은 어렵고 때로는 불가능한 일이기 때문에 엑셀, HTML 등으로 변환해야합니다.
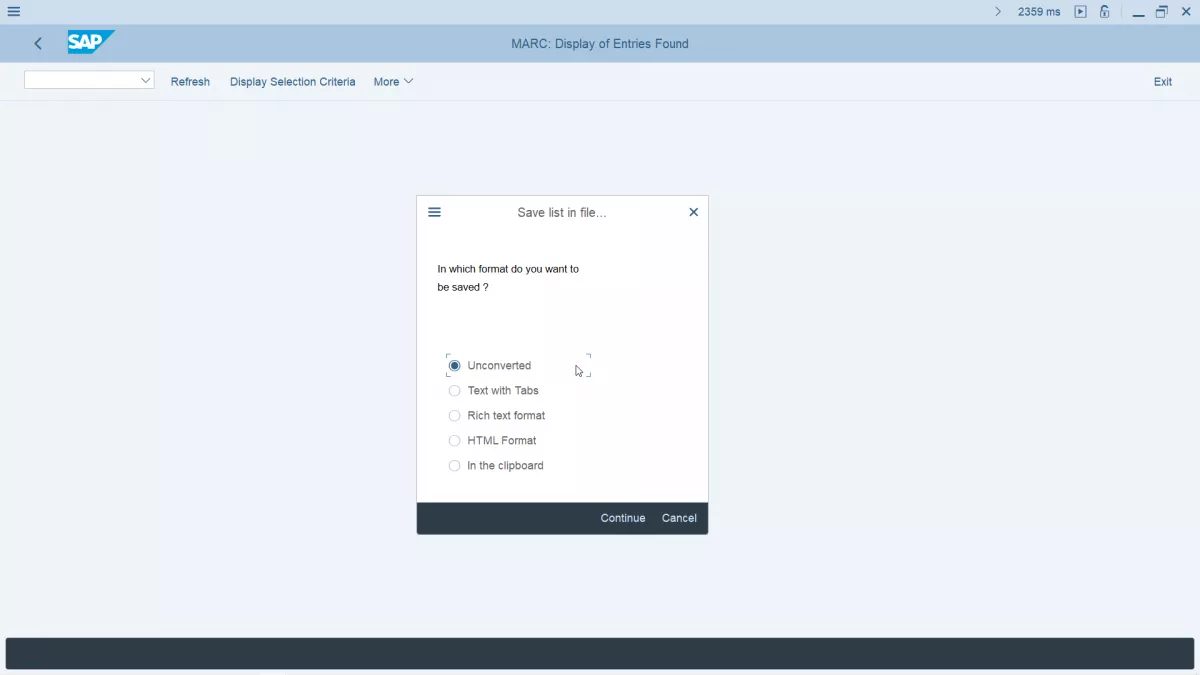
Unconverted 데이터를 SAP로 내보내기
많은 경우, HTML 또는 XL과 같은 데이터 내보내기가 SAP에서 작동하지 않는 이유는 이러한 레코드 유형을 사용하여 이러한 데이터 볼륨을 저장하는 것이 비쌉니다. SAP에서 작업 할 때 데이터를 저장하고 처리하는 가장 실질적인 방법은 Excel 대신 텍스트로 데이터를 내보낼 것입니다.
변환되지 않은 텍스트 또는 CSV로서 정보를 저장하는 것은 Excel 및 기타 변환 된 파일보다 많은 장점이 있습니다. 이것은 데이터를 형식화하고 위치 해야하는 위치에 대해 파일 코드에 정보를 유지할 필요가 없으므로 가능한 한 많은 공간을 저장함으로써 달성됩니다.
Excel에서 텍스트 파일의 주요 이점은 다음과 같습니다.
- CVS 및 텍스트 파일이 크게 가볍습니다.
- CSV 파일은 훨씬 빠르게 열립니다.
- 단순성으로 인해 CSV 및 TXT 파일을 열리고 거의 모든 디지털 장치에서 열 수 있습니다.
- 이러한 형식은 매우 유명하며 거의 모든 데이터 편집 소프트웨어에서 지원됩니다.
물론 Excel 및 변환 된 파일을 사용하는 것보다 이러한 형식을 사용하여 SAP 프로그램을 사용하는 것이 훨씬 편리합니다. Unconverted 텍스트의 형태로 파일을 저장하고 처리하는 것이 아직 확장되지 않은 경우 Excel에서 파일을 사용하는 것보다 훨씬 편리합니다. CSV 형식을 사용하여 SAP에서 큰 데이터로 작업하는 것이 중요한 이유가 있습니다.
- Excel Chews 숫자, 즉 쉼표로 구분 된 숫자를 하나의 숫자로 묶습니다. 이는 중요한 데이터가 손실되는 이유입니다.
- 15 자 이상의 큰 숫자는 Excel에서 지수 할 수 있으며 데이터가 손실됩니다.
- 어떤 경우에는 줄의 시작 부분에서 플러스를 제거합니다.이 경우 데이터 처리 문제가 발생합니다.
- 또한 문제와 데이터 손실을 초래하는 선행 0을 제거합니다.
- Excel 파일은 손상되거나 잠겨 있으며 PassFab과 같은 특수 소프트웨어,
- 또한 많은 다른 방법으로 데이터를 망쳐 놓습니다.
또한 SAP에서 작동하려면 원시 텍스트를 사용할 때 훨씬 쉬운 부분에 데이터를로드하는 것이 바람직합니다.
SAP에 업로드 할 때 부품으로 파일을 분할하는 것이 더 낫습니다.
위에서 언급했듯이 큰 데이터는 많은 저장 공간을 차지하는 믿을 수없는 정보입니다. 이러한 볼륨을 사용하면 네트워크를 통해 데이터를 보내는 것은 매우 어렵습니다. 인터럽트는 다운로드 속도를 0으로 재설정하고 트리거 트리거뿐만 아니라 트래픽을 낭비 할뿐만 아니라 많은 시간과 처리 전원을 다시 처리하고 파일을 보내는 데 많은 시간과 처리 능력이 필요합니다. 이러한 문제를 피하기 위해 텍스트 파일을 분할하고 여러 사본을 얻는 데 서비스를 사용하는 것이 매우 유용합니다. 이는 최종 사용자가 편리하게 볼 수 있습니다.
자주 묻는 질문
- 시스템 성능을 보장하기 위해 SAP에서 대형 데이터 파일을 관리하기위한 모범 사례는 무엇입니까?
- 모범 사례에는 데이터 저장 최적화, 정기적으로 이전 데이터를 보관하고 효율적인 데이터 검색 방법을 사용하는 것이 포함됩니다.